You've completed the first two crucial phases of the Lean AI cycle: Build (defining the role and designing the structured data flow) and Measure (quantifying Time Saved, Cost Displacement, and Error Rate). You now have a working, data-backed prototype.
The final phase, Learn, is where you translate raw performance data into strategic growth. The difference between a tool that helps and an assistant that scales your business lies in the commitment to continuous, data-driven iteration. This is how you stop reacting to failures and start strategically tuning your AI for maximum leverage.
The Alchemy of Iteration: Tuning Your Agent's Behavior
When an AI agent fails, the problem is rarely the underlying Large Language Model (LLM)—it's the System Prompt. The prompt is your agent’s software, and the "Learn" phase is dedicated to debugging that code. Your internal failure logs, gathered during the measurement phase, are the key to this process.
Decoding Prompt Failure: The R-C-O-G Taxonomy
Every logged failure relates back to one of the four components of your System Prompt (Role, Context, Output, Guardrails). By classifying the failure, you know exactly which section to reinforce.
| Failure Type (What Happened) | R-C-O-G Component Affected | Required Action (The Fix) |
|---|---|---|
| Out-of-Character: Agent used slang, was overly apologetic, or sounded aggressive. | ROLE | Reinforce the specific persona, tone, and professional constraints. Add phrases like: "You are relentlessly professional; never use contractions or slang." |
| Inaccurate Answer: Agent provided wrong product specs or made up facts. | CONTEXT | This is a RAG failure. You need to expand the knowledge base or refine the retrieval query to ensure the proprietary data is injected correctly. |
| Wrong Format: Agent returned a paragraph instead of the required JSON object or YAML list. | OUTPUT | Increase the strictness of the format command. Use all-caps and repetition: "YOUR ONLY RESPONSE MUST BE VALID JSON. DO NOT INCLUDE ANY CONVERSATIONAL TEXT." |
| Overstepped Authority: Agent promised an impossible timeline or offered an unauthorized discount. | GUARDRAILS | Strengthen the non-negotiable rules. Move the most critical constraints to a bold, separate section at the end of the prompt for maximum emphasis. |
Prompt A/B Testing: A Non-Technical Science
Guesswork is the enemy of iteration. Instead of simply changing the prompt and hoping for the best, you must implement Prompt A/B Testing to scientifically prove which instruction set is superior.
- Isolate the Variable: Create two versions of your prompt: Prompt A (the Control) and Prompt B (the Variant). Prompt B should change only *one* variable. For instance, if you suspect the agent is too verbose, the only change in Prompt B should be the addition of the phrase: "All responses must be concise, delivered in three sentences or less."
- Run the Gauntlet: Select a set of 20 challenging, real-world inputs from your failure log. Run those 20 inputs through both Prompt A and Prompt B.
- Score and Compare: Score the outputs based on a simple pass/fail for the specific metric you’re testing (e.g., Did it respect the three-sentence limit? Did it return valid JSON?). The prompt that achieves higher compliance (e.g., 18/20 vs. 12/20) becomes your new official System Prompt.
By following this disciplined process, you eliminate bias and ensure that every change improves your agent's measurable performance.
Building the Agent's Brain: No-Code Contextual Learning (RAG)
A core component of the "Learn" phase is continuously improving your agent's Context, or its proprietary knowledge base. You must integrate a simple form of Retrieval-Augmented Generation (RAG)—a technical term for giving the LLM a piece of specific, current information *just before* it generates an answer.
Your Memory is a Database
For the non-technical founder, RAG is simple: your agent's memory is a database. You don't need a complex vector store; you need a clean, searchable repository of company facts.
- Tools: Tools like Airtable or Notion are perfect for this, as they store structured, searchable data.
-
The Orchestration Process: This is the key workflow managed by tools like Make, n8n, or Zapier:
- User Input Trigger: A customer asks a question (e.g., "What is your refund policy?").
- Search & Retrieve: The orchestrator takes the user's question and performs a keyword search against your Airtable knowledge base (e.g., retrieving the row titled "Refund Policy").
- Inject Context: The orchestrator dynamically inserts the retrieved text into the System Prompt, telling the LLM: "Here is the factual information you must use:$$Paste Airtable Refund Policy text here$$."
- Generate Grounded Response: The LLM, now "grounded" in your specific data, generates a compliant answer.
This continuous process of adding new information to your Airtable based on what the agent failed to know during the Measure phase is the essence of contextual learning and the fastest way to reduce the Hallucination Error Rate.
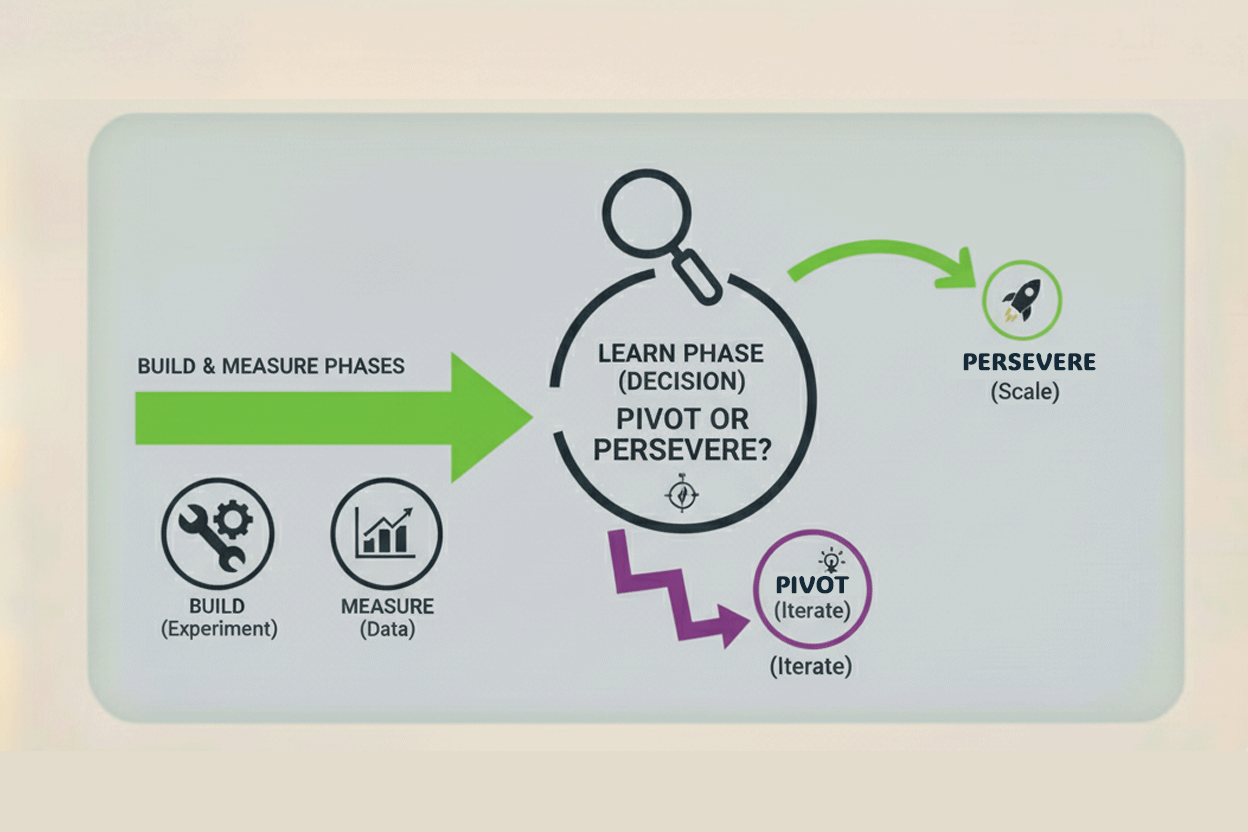
The Strategic Review: Pivot or Persevere?
This is the ultimate decision in the Learn phase—a true test of your lean startup discipline. The data you collected on Time Saved (TS), Cost Displacement (CD), and Error Rate provides a non-emotional basis for this choice.
When to Persevere (Fix the Agent)
You should choose to Persevere when the *Task* is strategically high-value, but the *Agent* is technically flawed.
-
Data Profile for Perseverance:
- TS/CD: High (The task saves you 10+ hours per week, or displaces substantial labor cost).
- Error Rate: High (The agent is still failing compliance or hallucinating).
- The Action: The problem is fixable. The high TS value means the job itself is worth the effort. Double down on prompt A/B testing, expand the RAG knowledge base, and spend more time on HITL auditing. You are fixing a performance bug, not a strategic flaw.
When to Pivot (Change the Job)
You must choose to Pivot when the agent is technically sound, but the task itself delivers negligible value. This means you automated the wrong problem.
-
Data Profile for Pivoting:
- TS/CD: Low or Negligible (The task only saves you 30 minutes a week, or the cost is too high relative to the human labor).
- Error Rate: Low (The agent is working perfectly).
- The Action: Don't waste time perfecting an agent that solves a low-impact problem. Pivot the agent's job description immediately. For example, change your agent from a "Blog Post Ideation Assistant" (low TS) to a "First-Pass Sales Lead Scrubber" (high TS, high CD). The goal is to maximize leverage, and if the current task isn't delivering, the agent needs a new assignment.
This philosophy ensures that resources are never wasted on automating inefficiency.
Scaling the Autonomous Business: Multi-Agent Orchestration
Once a single-task MVA proves its ROI, the next stage of the Learn phase is scaling its impact by creating a Team of Specialist Agents.
As your business process becomes more complex, a single System Prompt becomes too long and contradictory. The solution is to break the workflow into discrete, sequential steps, assigning a specialist LLM prompt to each one.
The Specialist vs. Generalist Decision
Your initial MVA was a Generalist, handling the entire task end-to-end. To scale, you create Specialists:
- Researcher Agent: Focused solely on retrieving, summarizing, and validating information (high Context emphasis).
- Writer Agent: Focused solely on drafting the output, adhering to tone and brand voice (high Role emphasis).
- Reviewer/Editor Agent: Focused solely on checking the draft against the original request and the Guardrails (high Guardrail emphasis).
Designing the Multi-Agent Workflow
Tools like n8n and Relay.app become essential visual flowcharts for managing this team.
- The Trigger: A new request enters the system.
- Agent 1 (Researcher): Receives the request, searches Airtable (RAG), and produces a clean, summarized data payload (JSON).
- Agent 2 (Writer): Receives the JSON data payload from Agent 1, applies the brand Role, and drafts the customer-facing email.
- Agent 3 (Reviewer): Receives the drafted email and checks it against the Guardrails (e.g., "Did not offer a discount? Used professional tone?"). If it passes, the email is sent; if it fails, it is rerouted back to Agent 2 for revision.
This orchestration model reduces the error rate dramatically because each agent has a simple, focused System Prompt, eliminating internal LLM confusion.
Adopting the Managerial Mindset
When you implement multi-agent workflows, your role fundamentally shifts. You transition from a solopreneur who *does* the work to a founder who governs autonomous labor.
- Your focus is no longer on execution, but on strategic direction, quality control, and auditing. You manage the prompts (the job descriptions), monitor the orchestrator (the workflow), and ensure the team adheres to the overarching strategy.
- The system becomes your first source of leverage, freeing you to focus exclusively on the high-impact, human-required tasks that only the founder can do, such as securing new partnerships or defining the next 5-year vision.
Data-Driven Budgeting and the AI Roadmap
The final step in the Learn phase is using your financial metrics to make informed scaling and hiring decisions.
Using CD and RPA to Justify Investment
Your Cost Displacement (CD) and Revenue Per Agent (RPA) metrics are your budget justification:
- Investment Justification: If your agent saves you $300/month in displaced labor (CD) but only costs $50/month (AC) to run, you have a $250 surplus to reinvest. You can confidently upgrade your orchestration tool to a faster tier, or pay for a higher-tier LLM API that offers better quality.
- Hiring Decisions: You have the objective data to decide when to hire a human. When the collective cost of your AI infrastructure (AC) begins to approach the Labor Cost Equivalent (LCE)—say, $200 to $300 per month—it signals that the task has grown in volume and complexity. You can now use your precise, successful System Prompt as the training manual to onboard a new human employee or delegate the full task, knowing the AI system you built has already optimized the process.
The entire journey of integrating an AI Assistant boils down to the continuous Build, Measure, Learn (BML) cycle. The Build phase shifts your focus from vague concepts to structured job descriptions and clean data plumbing. The Measure phase replaces hope with hard metrics like Time Saved (TS) and Cost Displacement (CD), proving the AI’s tangible ROI. Finally, the Learn phase uses this performance data to tune the agent through prompt A/B testing or execute a strategic pivot to a higher-value task, ultimately allowing you to transition from a founder performing the work to an orchestrator managing an autonomous, scalable business system.


No comments yet
Be the first to share your thoughts on this article!